【初心者向け解説】標準入出力

初めに
Linuxでは、通常のファイルと同時に、ディスプレイへの出力やキーボードからの入力を扱うことができます。
つまり、キーボードからの入力もファイルの読み込みも同等に扱い、ディスプレイへの出力もファイルへの書き出しも同等に扱います。このような、データの入出力に伴うで0たの流れのことをストリームと呼びます。
Linuxではデータをストリームとして扱うため、3つの基本的なインターフェースが定められています。標準入力はプログラムへの入力ストリームであり、デフォルトはキーボードです。標準出力はプログラムからの出力ストリームであり、デフォルトは画面(端末)です。標準エラー出力はプログラムの正常動作とは関係のないエラーメッセージなどの出力ストリームであり、デフォルトは画面(端末)です。これらの標準入出力を自在に切り替えることにより、同一のプログラムに様々な動作を期待することができます。
| 番号 | 入出力名 | デフォルト |
|---|---|---|
| 0 | 標準入力 | キーボード |
| 1 | 標準出力 | 画面(端末) |
| 2 | 標準エラー出力 | 画面(端末) |
辞書での定義は?
IT用語辞典では以下のような記載がありました。
(Weblio辞書より)
標準入力とは、UNIX環境でのキーボードに相当する装置のことである。
(e-Wordsより)
標準入力とは、コンピュータ上で実行されているプログラムが、特に何も指定されていない場合に標準的に利用するデータ入力元。
辞書によって説明はまちまちですが、なんとなく理解できるような、できないような。。。「結局『標準』って言われてもなに!?」という人もいるのではないでしょうか。
そもそも入力と出力ってなに?
標準入力・標準出力というのは「標準」「入力と出力」です。そもそも入力と出力とはなにか?
一般に入力・出力というと何かを入れる、出すといったものになるかと思いますが概念としては広いです。
そこでここで扱っているのはファイルとしての入力・出力、つまりファイルからデータを読み込む、ファイルにデータを書き込むといった操作やデータの流れを指します。
「あれ? でもキーボードから打ち込んでもファイルなの?」と違和感を感じられるかも知れません。が、これはある意味Linux ( UNIX系OS ) の流儀です。通常のファイルも含め、バイト列としてデータを読み込んだり書き込んだり、どちらかができるものをファイルとして扱うという決めごとなのです。このファイルの中には、ネットワーク通信を行うための、ソケットと呼ばれるモノすら含まれます。
扱う対象によって、できる操作というのは色々変わってきます。例えば通常のファイルであれば、最初からある程度データを読み込んだ時点で、また先頭に戻って読み込み直すといった操作ができますが、磁気テープという装置 ( /dev/st0等のファイル名の特殊ファイル ) は、一度データを読み出すと、明示的にテープを巻き戻すコマンドを実行しないと、また最初から読むことはできません。
ですが、「順々にデータをバイト列として取り出せる」「順々にデータをバイト列として流し込める※」どちらかあるいは両方を行うことができるのは共通です。この性質の持つものを、なんであれファイルという共通の概念で扱いましょう、ということです。
明示的な入力・出力
さてそれでは、入力・出力の例としてどのようなものがあるでしょうか。例としてLinuxで良く使うcpコマンドを見てみます。cp file1 file2というコマンドを実行すると、file1というファイルをfile2にコピーするという処理を実行します。これは、file1からファイルの内容の読み込みを行い、file2へ書き込みを行うというもので、次の図のように入力・出力が発生します。
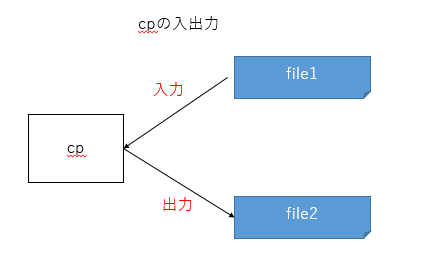
この時、cpは明示的にfile1を入力元、file2を出力先として使います。いや、コマンドでそう指定したんだから当たり前だろうと思うかも知れませんが。もう一例見てみます。
今度はgzip file1というコマンドを実行した例です。同じようにfile1を入力元とし、今度出力先はfile1.gzという圧縮ファイルとなります。
※圧縮処理が終わったあと、gzipはfile1を削除してしまいますが、そのことは置いておきます。
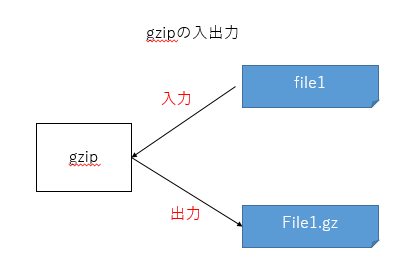
file1.gzを出力先にするのはそれは当たり前だろうと思うでしょうか。file1をターゲットに選んだんだから、それに合わせて.gzを付けたんだろう、とも言えますし、こちらは特に何もしていしなくてもgzipが勝手にファイル名を考えたんだ、とも言えます。
いずれにせよ、コマンドを指示した側の思惑があるにせよ、これらの例ではcp,gzipが入力元・出力先のファイルを選んでいるというところは共通しています。これを明示的と、ここでは表現しています。
なお、誤解があるといけないのは、入力・出力というのはファイルそのものではないというところです。ファイルに対して読み書きするためのデータの経路、そちらの方を指しています。
※これはOSの内部的にはファイルディスクリプタという数値で管理されています。
暗黙の入力・出力
では明示的の逆は考えられないでしょうか。つまり、暗黙の入力・出力です。
今度は、cpコマンドにちょっとオプションを追加してみます。
$ cp -v file1 file2
'file1' -> 'file2'
-vオプションの影響により、行われたコピー処理のサマリーが表示されます。…ということは、上で挙げたfile1,file2の入力・出力とは別に、この表示用の何かメッセージの出力が発生しているということです。
※この段階ではその出力先は詳らかとしません。
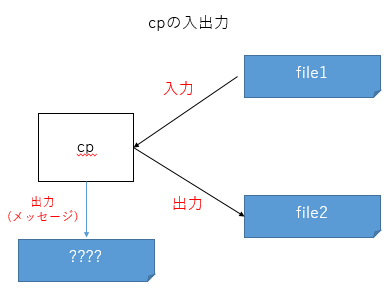
標準入力・標準出力
ここまでで明示的、暗黙の入力・出力の2種類を挙げたことで、既にお察しのことかもしれませんが、標準入力・標準出力とは実はこの暗黙の入力・出力のことを指します。
言い換えると、コマンド/アプリ側で入力元・出力先を明示することなく使用できる入力・出力のことです。
これにはもう少し深い意味が含まれていることに注意する必要があります。それは、次のようなコマンド/アプリ開発者と使用者との間の約束事です。
- アプリ側では、標準入力・標準出力が暗黙の入力・出力として使えることを前提として良い。
- 標準入力・標準出力がどんなファイルに結び付けられているか、アプリ側で意識する必要はない。それはアプリ実行者が良いように用意しているはずだ。
- アプリ実行者には、そのアプリがどのように標準入力・標準出力を使うかを意識して、事前に適切な入力元・出力先を用意する義務がある。
なぜこのような設計にしたのか。それはLinuxの元となっているUNIXの思想の一部ではあると思うのですが、ただこうすることで、アプリ側はデータの流れがどこに繋がっているかを意識せず、データをどう加工するかに専念することができる、使用者側はアプリを使ってどのようにデータの流れを調整するかに注力する、そのような役割分担ができます。実際、パイプという機能を活用して処理を実現する場合、この役割分担を強く意識します。
-
前の記事

【初心者向け解説】メタキャラクタ 2021.10.22
-
次の記事

【Active Directory】Windows Server 2019をインストールする (その1) 2021.10.27