Amazon Redshift Black Beltまとめ
- 2021.06.01
- AWS

こちらは2020/03/18には行われたAmazon RedshiftのBlack beltの動画のまとめになります。
どちらかというと個人向けにまとめたものになりますが、AWS SAAなどの資格取得に向けて勉強されている方などの助力になればとも思っております。
Amazon Redshift 概要
Amazon Redshiftとは
高速でスケーラブルで費用対効果の高いデータウェアハウスおよびデータレイク分析マネージドサービス

Amazon Redshiftのユースケース
主に大容量のデータを高速に集計・分析する必要があるワークロードに活用

Amazon Redshiftを中心としてデータ分析パイプラインの例
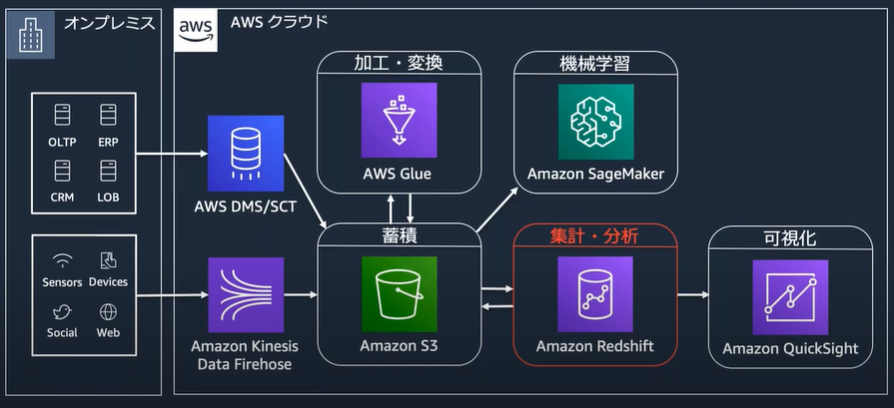
Amazon Redshift アーキテクチャ
Amazon RedshiftはPostSQLがベースになっています。
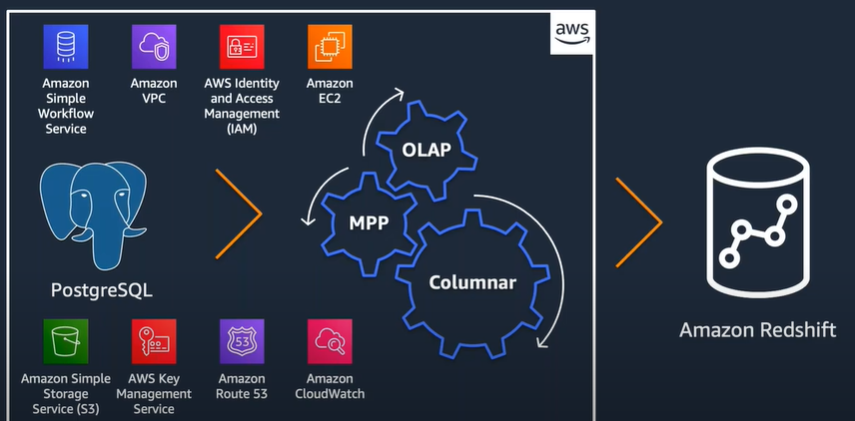
Amazon Redshift のアーキテクチャ
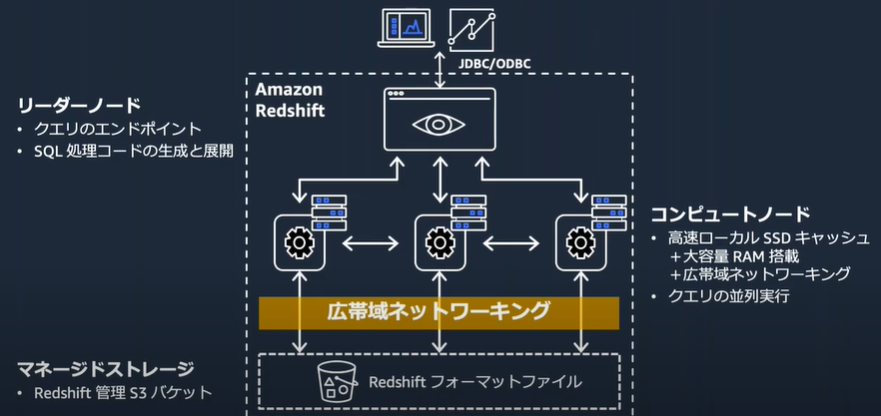
- コンピュートとストレージを分離しスケーリングと支払いを独立
- データは永続ストレージとしてのS3とキャッシュとしてのローカルSSDに格納される
- アクセス頻度の高いブロックはキャッシュにとどまり、あまりアクセスされないブロックは自動的にキャッシュアウト
クエリの実行
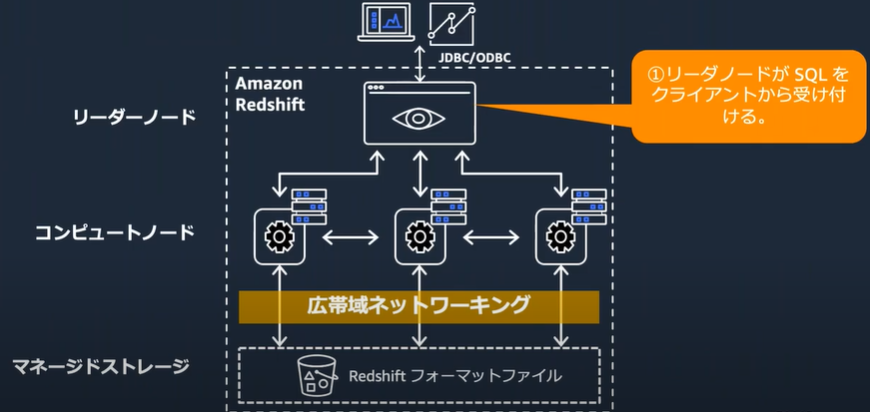
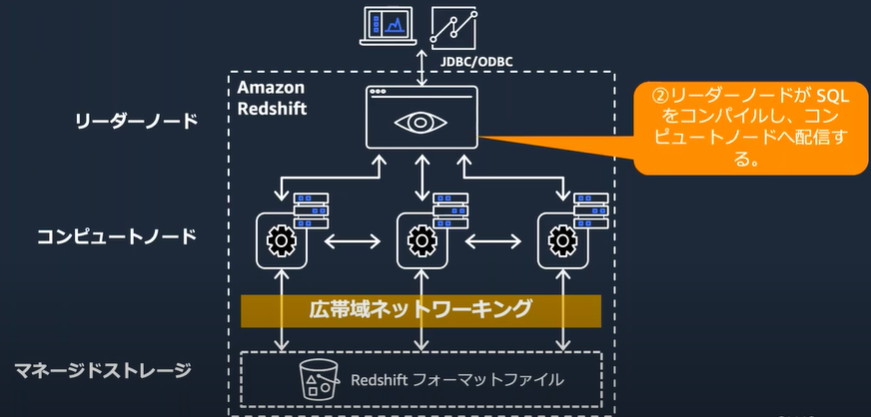
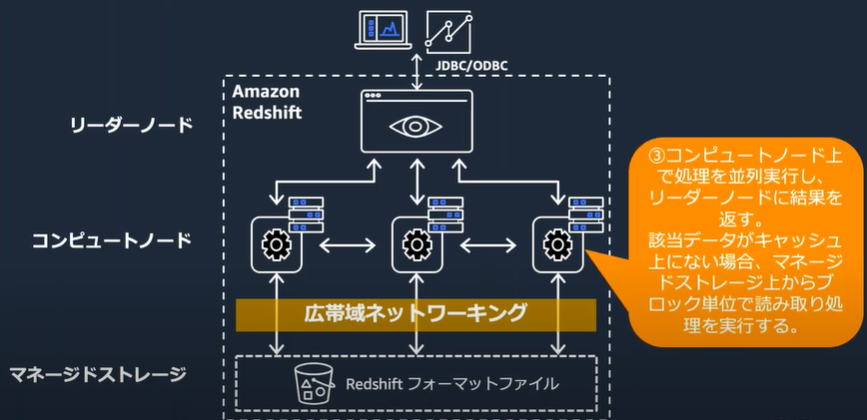
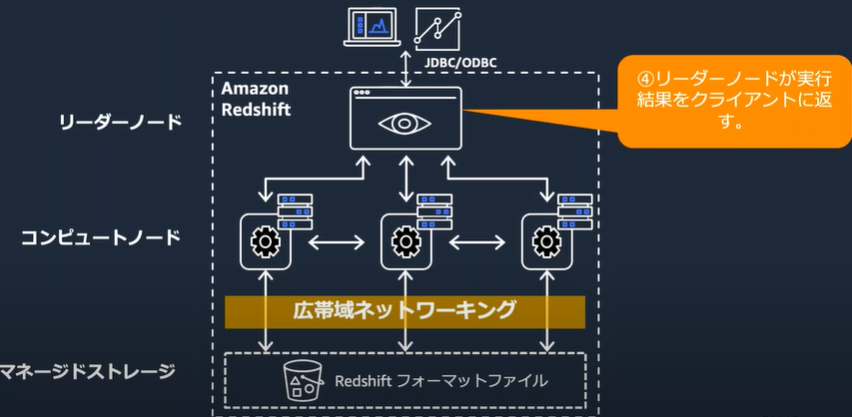
データロードとアンロード
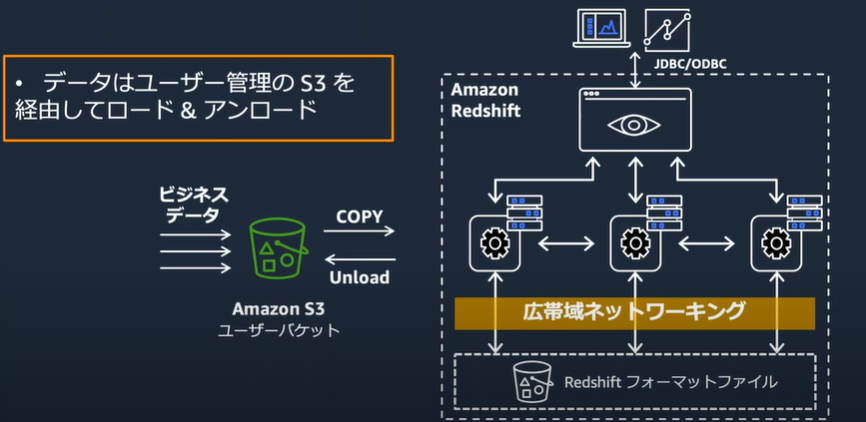
データはユーザ管理のAmazon S3で受けてbulk loadで書き込むのが一般的。
コピーコマンドで書き込む
Amazon Redshift の特長
ハイパフォーマンス
列指向ストレージ
Redshiftは列指向ストレージを採用
・データは列ごとに格納/必要な列のみの読み取りが可能に
・大容量データへのアクセスが必要となる分析クエリのボトルネックとなるディスクIOを削減
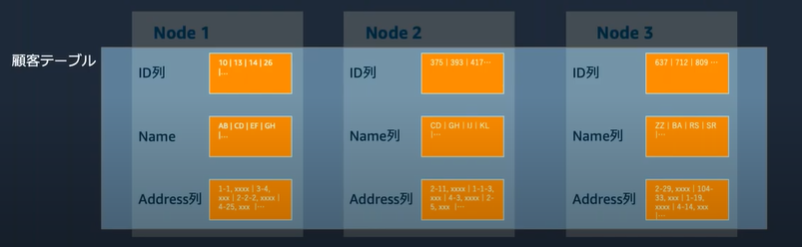
列指向ストレージの検索例

データ圧縮
・列の圧縮を行うことで、一度のディスクアクセスで読み込めるデータ量が多くなり、速度の向上が見込める
・圧縮のエンコード(アルゴリズム)が13個用意されており、CREATE TABLEで各列に選択することが可能
・ANALYZE COMPRESSIONコマンドを利用することにより、既存のテーブルの各列に最適な圧縮を確認することが可能
・エンコードタイプ変更したい時には、テーブル再作成&INSERT-SELECTで対応
圧縮が未指定の場合、圧縮エンコードが自動割り当て

データ圧縮の設定例


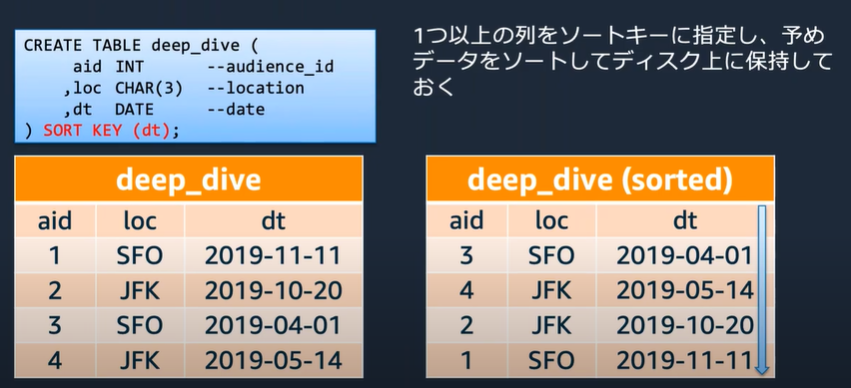
ソートキー
1MBブロックサイズ
・分析ワークロード向けに、データ格納ブロックサイズを大きく確保(1MB/block)することにより、ディスクI/Oを効率化している
・RDBMSの一般的なデータブロックサイズは8kBから32KB/block
・各列のブロックは13の圧縮エンコーディングタイプのうちの1つを指定して個別にエンコードされる
ゾーンマップ
・データが格納されている各ブロック(1MB)に関するメタデータをリーダーノードのインメモリ上に格納
・各ブロック上に存在する最小値、最大値を保持
・クエリの内容に応じて、処理に不必要なブロックは読み飛ばすよう効率的なアクセスを実現
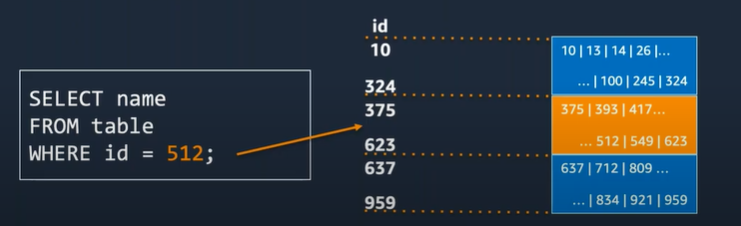
ソートキーとは
・ゾーンマップ機能を活用してディスクI/Oを削除し、クエリパフォーマンスを向上させるため、データソートは重要なポイント
・データをどの列にソートするかを、テーブルごとにソートキーとして指定
・頻繁に使われる絞り込み(WHERE句)条件キーが筆頭候補
・一般的には日付などの時系列やIDが多い
・実際のクエリパターンと処理優先度などから決定
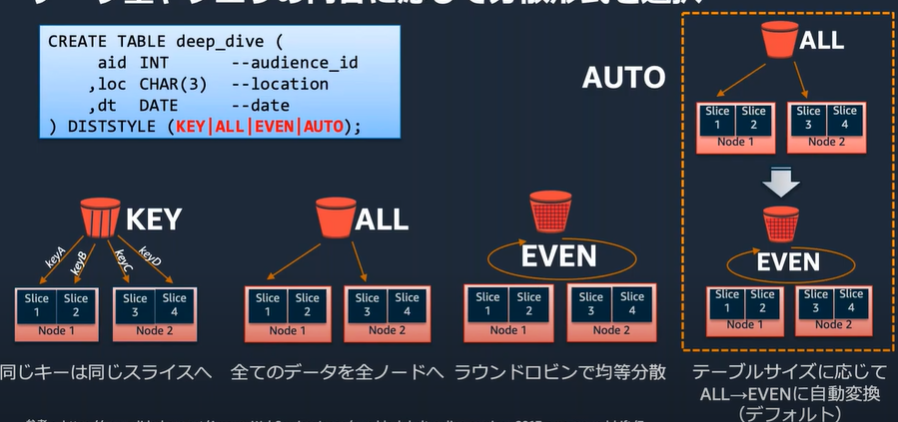
データ分散
データ量やクエリの内容に応じて分散形式を選択
ハイパフォーマンスを支えるその他の機能

フルマネージド
構築・運用の手間を削減
・1画面の設定のみで起動
・ノード数やタイプは後から変更可能
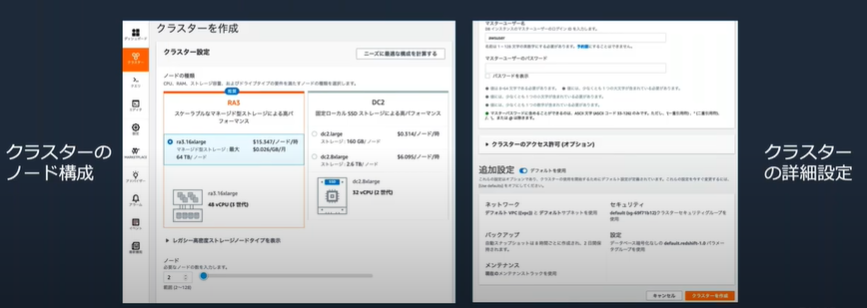
構築・運用の手間を削減
・自動バックアップやモニタリング機能を内蔵
・GUI
・API経由で操作も可能
・パッチ適応も自動実行
・メンテナンスウィンドでパッチの適用時間帯を指定可能
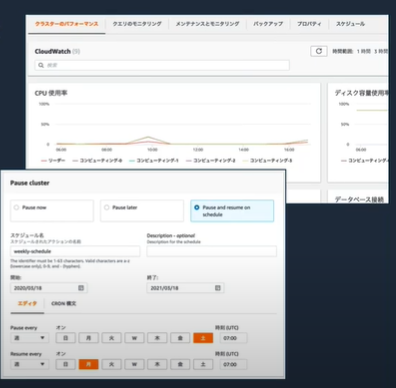
・スケジューリング機能
・クラスターサイズの変更
・クラスターの一時停止と再開
機械学習ベースの自動最適化によるクエリ性能の向上

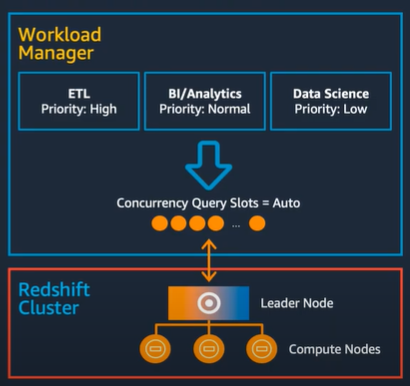
ワークロード管理:キューとスロット
・ユーザはワークロードの種類などにもとづいてキューを複数個作成することが可能
・各キューにはクラスターが使用できるメモリの一部を割り当てる
・クエリ割り当てルールにより、各クエリが各キューに割り当てられる
・スロットは、クエリを処理するために使用されるメモリとCPUの単位となり、各キューごとに設定可能
・スロットを増やすと並列度は上がるが、スロット当たりの割り当てメモリが減る

自動ワークロード管理とクエリ優先度で効率的に処理
・ワークロード管理の設定を自動化(デフォルト)することで、クエリへのメモリ割り当てを最適化するために並列スロット数を自動的に決定
・クラスターのリソースを効率よく配分することをサポート
・スループットとパフォーマンスの最大化
・機会学習を活用して、リソース要求を元にしたクエリの分類を実施
・ビジネスの優先順位に基づいてワークロード毎のパフォーマンスを調整可能
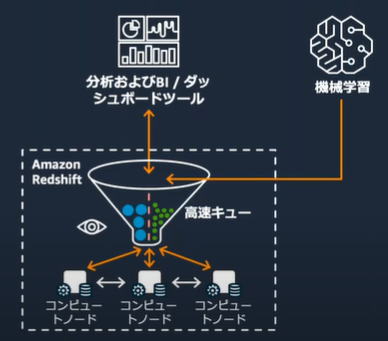
ショートクエリアクセラレーションによる高速化
実行時間の短いクエリのスループットを高速化
1.機械学習によっていクエリの実行時間を予測する
2.ショートクエリと判断されたクエリは専用の高速キューにルーティングされる
3.リソースはショートクエリのために動的に確保される
拡張性&柔軟性
コンピュートノードの追加で拡張可能
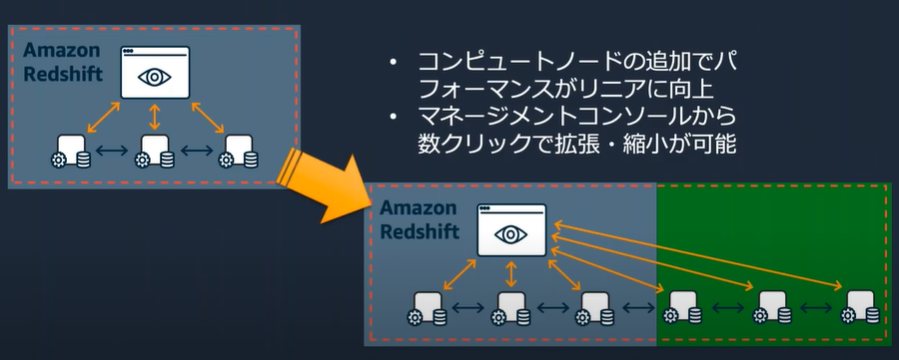
数分でクラスターの伸縮を実現する
・既存のRedshiftクラスター上にノードを追加
・繁忙期にクエリを高速に処理
・データ転送にかかる時間を最小化
・コンピュートとストレージをオンデマンドでスケール
・スケジュール設定可能

ピーク時にコンピュートを自動拡張する
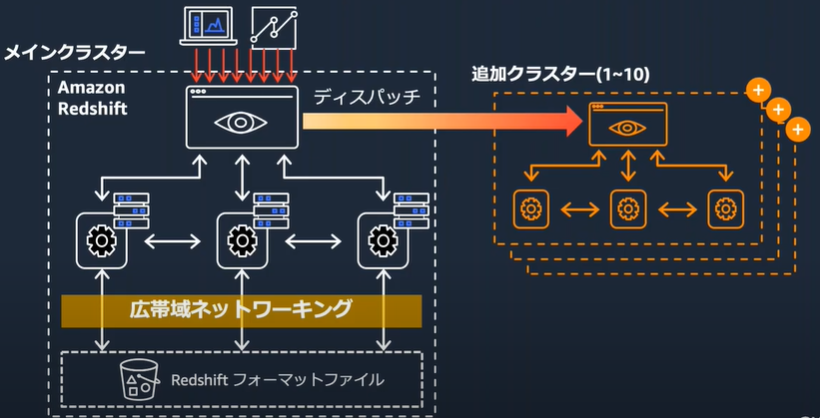
データレイク&AWSサービスとの親和性
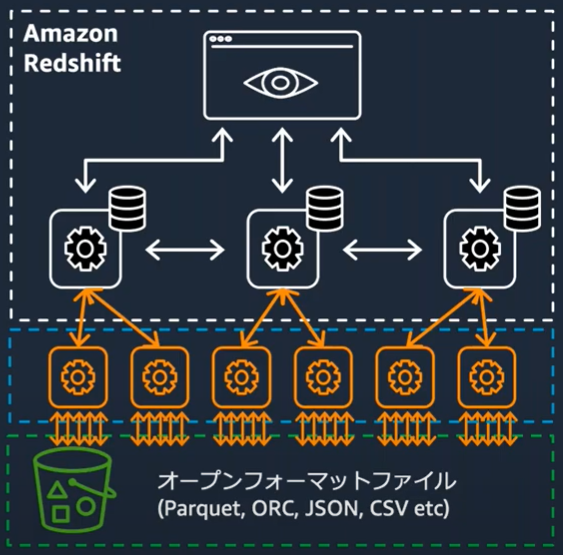
RedSpectrumでアーキテクチャをデータレイクに拡張

Redshift Spectrumのアーキテクチャ
・事前のデータロード不要でS3上のデータに対して直接SQLを実行
・RedshiftとS3それぞれに存在するデータを結合可能
・オープンファイルフォーマット対応(Parquet、ORC、JSON、Grok、Avro、およびCSVなど)
RA3とRedshift Spectrumとの違い・使い分け
| RA3 | Redshift Spectrum | |
|---|---|---|
| ストレージ | Redshift管理のS3領域を使用 | ユーザ管理のS3領域を使用 |
| データフォーマット | Redshift独自のフォーマット | オープンフォーマット |
| データへのアクセス | Redshiftからのアクセスのみ | 他のAWSサービスからもアクセス可 |
| データの更新 | DML UPDATEに対応 | DML UPDATEには非対応 |
| コスト | Redshiftインスタンス料金+ マネージドストレージ料金 | Redshiftインタンス料金+S3ストレージ格納料金+Spectrumスキャン容量料金 |
| 特徴 | RA3のマネージドの拡張であり、その背後でS3の技術が使われているが、利用時にS3を意識する必要はない | データレイクとしてのS3にアクセスする機能であり、データレイクを介した他サービスとの連携のために今後も重要な機能であり続ける |
| 使い分け | これまでRedshift内のデータ増加を抑制する目的で過去データを削除したり、S3にデータをオフロードしてSpectrumを活用していた場合は、RA3ストレージを活用 | すべてのデータがデータレイクにあり、Redshiftだけではなく他のサービスからも同じデータにアクセスする要件がある場合はSpectrumを活用 |
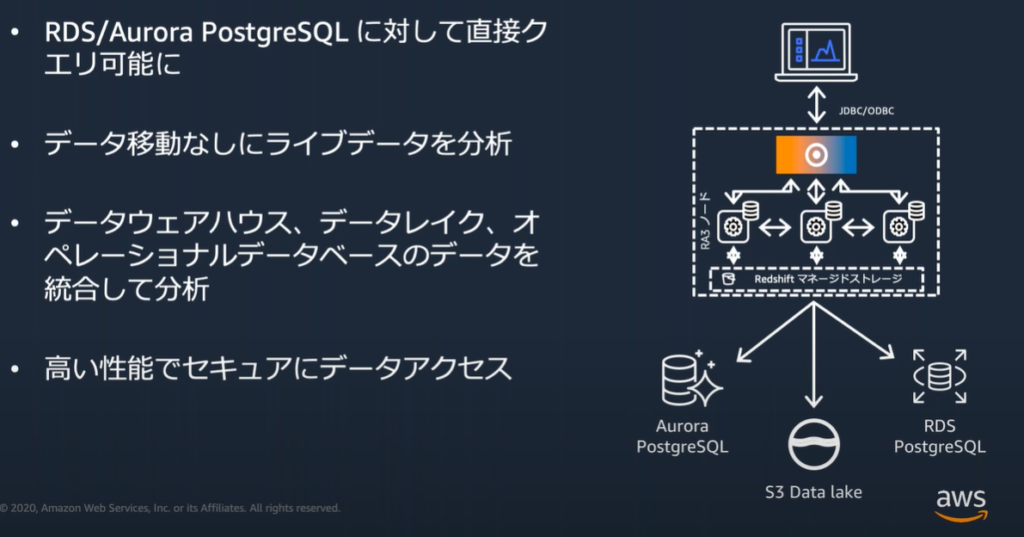
データレイクエクスポートでデータを共有

フェデレーテッドクエリ(プレビュー中)
高いコスト効果
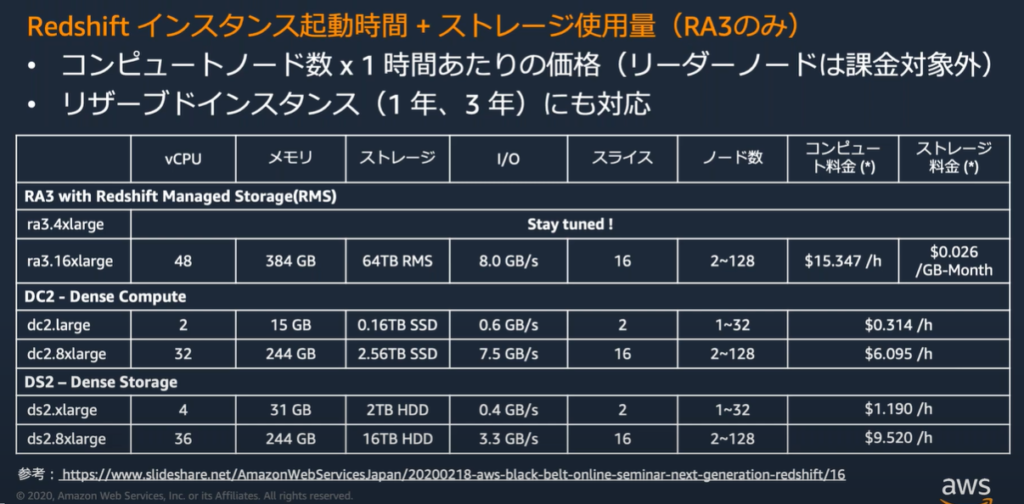
Amzon Redshiftの料金
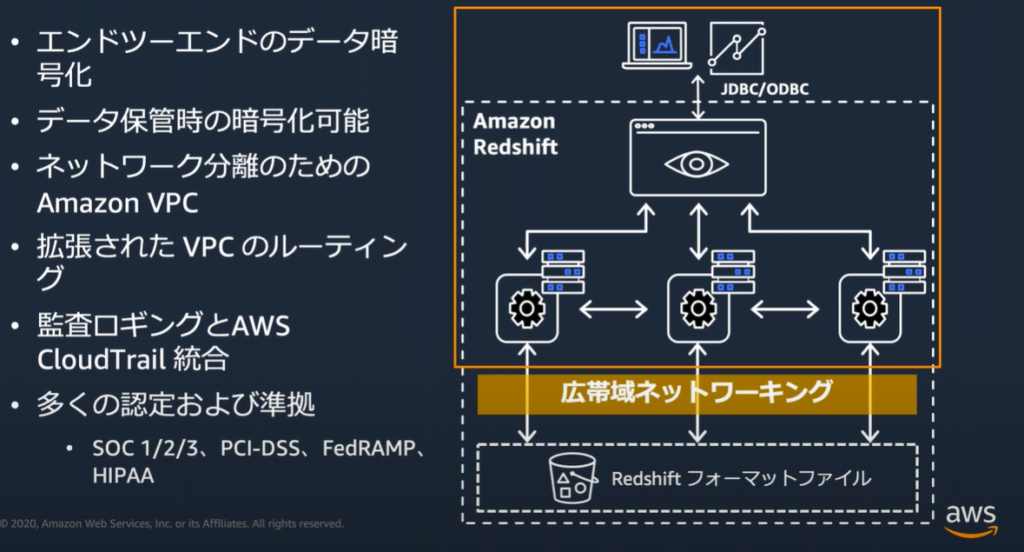
セキュリティ&コンプライアンス
ビルドインされたセキュリティ機能
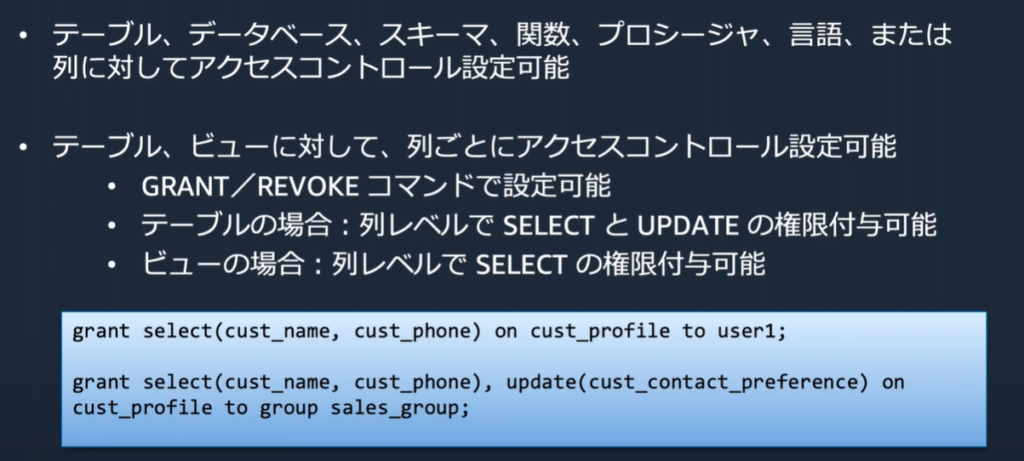
アクセスコントロール
まとめ
・Redshiftは、高速、スケーラブルで費用対効果の高いデータウェアハウスおよびデータレイク分析マネージドサービス
・多くのメンテナンスタスクやデータ配置が自動化されており、煩雑になりがちなデータウェアハウスの運用を簡単にする
・自動テーブルメンテナンス
・自動ワークロード管理
・アーキテクチャの特長を踏まえ、ユーザー側で設定をカスタマイズすることによって、さらに快適な環境②していくことも可能
-
前の記事

Amazon SQS Black Beltまとめ 2021.05.31
-
次の記事

Windows Server の共有フォルダをEsxiにマウントする 2021.06.07